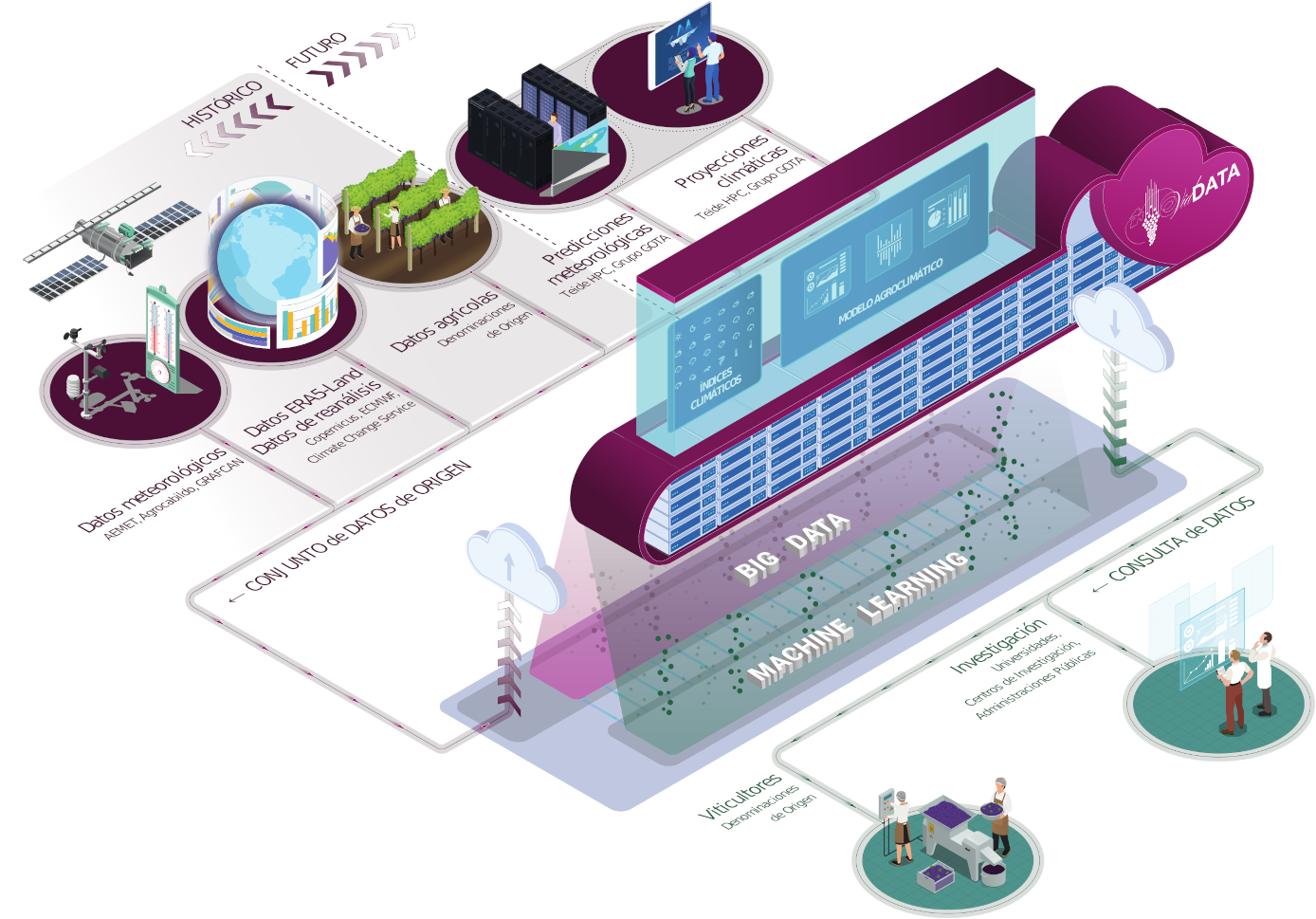
VidDATA es una herramienta esencial para los viticultores que buscan optimizar la gestión de sus viñedos y adaptarse al cambio climático. Al proporcionar información meteorológica y climática de alta resolución, junto con análisis detallados de rendimiento, VidDATA permite tomar decisiones más informadas sobre prácticas como la irrigación, la poda y la cosecha. Esta plataforma no solo beneficia a los productores individuales, sino que también es una herramienta esencial para la investigación científica y la toma de decisiones políticas. Al proporcionar datos sólidos y análisis rigurosos, VidDATA contribuye a mejorar la comprensión de los impactos del cambio climático en la viticultura y a desarrollar estrategias de adaptación más efectivas a nivel regional y nacional. VidDATA es, en definitiva, un puente entre la ciencia, la política y la práctica vitivinícola, ayudando a garantizar la sostenibilidad y la competitividad del sector a largo plazo.
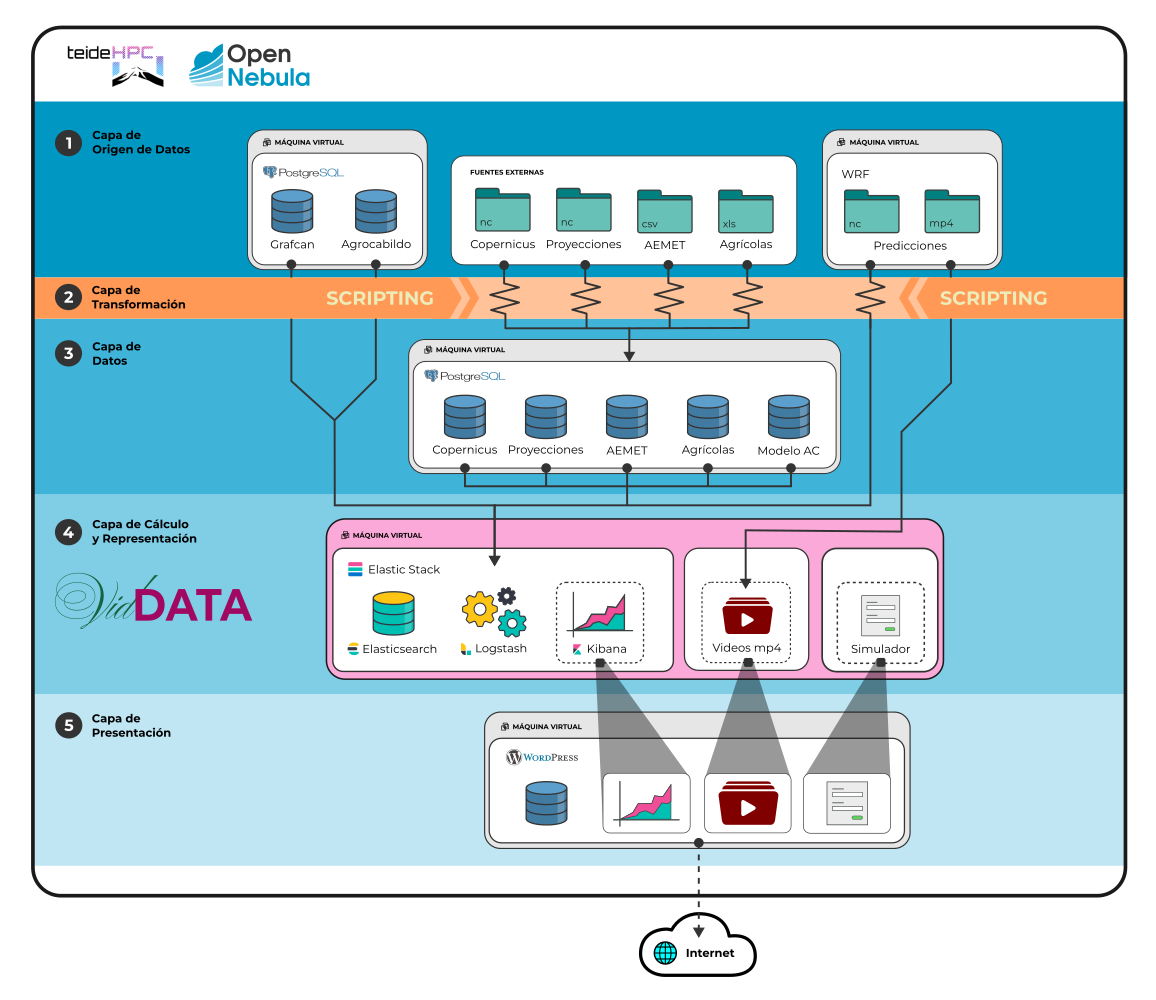
VidDATA se sustenta en una arquitectura tecnológica sólida y escalable, diseñada para gestionar grandes volúmenes de datos meteorológicos y agronómicos. Desde la captura y almacenamiento de datos de origen hasta la generación de visualizaciones intuitivas, la plataforma integra una serie de componentes interconectados que trabajan en conjunto. Esta arquitectura permite procesar y transformar datos de manera eficiente, garantizando la calidad y la fiabilidad de la información presentada. Su diseño modular y configurable facilita la incorporación de nuevas fuentes de datos y la adaptación a las necesidades cambiantes del sector vitivinícola.
Capacidad técnica y tecnológica
Una plataforma tecnológica de gran capacidad y de altas prestaciones, como es VidDATA, se estructura en capas físicas y lógicas que colaboran para ofrecer un rendimiento óptimo y escalable. La capa física comprende los componentes de hardware, como servidores, centros de datos y redes de alta velocidad, que proporcionan la infraestructura necesaria para soportar grandes volúmenes de datos y garantizar la disponibilidad y seguridad del sistema. Por otro lado, la capa lógica incluye el software y las aplicaciones que gestionan la lógica de negocio, procesamiento de datos y herramientas de análisis avanzadas. Estas capas lógicas operan sobre la infraestructura física, permitiendo la interacción entre los datos, los usuarios y los procesos. La adecuada integración entre ambas capas es fundamental para que la plataforma pueda responder eficientemente a las demandas de procesamiento y almacenamiento, manteniendo una operación fluida y confiable en entornos de alta exigencia.
El Instituto Tecnológico y de Energías Renovables, ITER, S.A. dispone de la infraestructura física y de las capacidades técnicas adecuadas para el desarrollo y puesta en marcha de una plataforma tecnológica de estas características.
Impulsado por el Cabildo Insular de Tenerife, se creó en 1990 con el objetivo de promover el desarrollo sostenible y la innovación. En la actualidad es un centro de investigación de referencia internacional en energías renovables, ingeniería, telecomunicaciones, medio ambiente y genómica.
El Datacenter D-ALiX es un centro de procesamiento de datos ubicado en las instalaciones del Instituto Tecnológico y de Energías Renovables, ITER, S.A..
Es una de las infraestructuras clave del proyecto ALiX, de la isla de Tenerife y de toda Canarias, ya que recibe los cables de fibra óptica submarina de comunicaciones con otras partes del mundo y distribuye las comunicaciones a nivel insular e interinsular.
La interconexión entre la infraestructura utilizada para albergar la plataforma VidDATA y la red de difusión se realiza en la sala de interconexión del D-ALiX.
El supercomputador TeideHPC (High Performance Computing) fue financiado por el programa INNPLANTA 2011 del Ministerio de Innovación y Ciencia, con cargo a Fondos FEDER y ocupando, en ese momento, el puesto 138 en la lista Top 500 de superordenadores de noviembre de 2013.
Alojado en el Datacenter D-ALiX, este supercomputador virtualiza todos los sistemas que conforman la plataforma VidDATA, así como la aplicación de los modelos WRF para el cálculo de las proyecciones climáticas y las predicciones meteorológicas.
Capa lógica
OpenNebula es una plataforma cloud computing para administrar infraestructuras centro de datos heterogéneas distribuidas. La plataforma OpenNebula gestiona la infraestructura virtual de un centro de datos para construir implementaciones privadas, públicas e híbridas de infraestructura como servicio.
Docker es un proyecto de código abierto que automatiza el despliegue de aplicaciones dentro de contenedores de software, proporcionando una capa adicional de abstracción y automatización de virtualización de aplicaciones en múltiples sistemas operativos.
PostgreSQL, también llamado Postgres, es un sistema de gestión de bases de datos relacional, orientado a objetos y de código abierto, que permite el acceso a una tabla mientras un proceso escribe en la misma sin necesidad de bloqueos, dando a cada usuario una visión consistente.
Python es un lenguaje de alto nivel de programación interpretado cuya filosofía hace hincapié en la legibilidad de su código. Se trata de un lenguaje de programación multiparadigma, ya que soporta parcialmente la orientación a objetos, programación imperativa y, en menor medida, programación funcional. Es un lenguaje interpretado, dinámico y multiplataforma.
R es un lenguaje y entorno para gráficos y computación estadística. Es un proyecto GNU similar al lenguaje y al entorno S y puede considerarse como una implementación diferente de este. R proporciona una amplia variedad de técnicas estadísticas y gráficas y es altamente extensible.
Motor de búsqueda y análisis en tiempo real que escala horizontalmente, ofrece búsqueda full-text y estructurada, análisis avanzado y alta disponibilidad para explorar datos complejos.
Herramienta flexible de ingesta de datos que centraliza la recolección desde diversas fuentes, aplica transformaciones y enriquecimientos, y los envía a Elasticsearch de forma confiable.
Plataforma de visualización interactiva que permite crear dashboards personalizados, realizar análisis exploratorios, generar reportes y gestionar el stack de ELK, facilitando la comprensión de los datos.
Usamos cookies para asegurar que te damos la mejor experiencia en nuestra web. Si continúas usando este sitio, asumiremos que estás de acuerdo con nuestra política de cookies